Key analysis tools
DCA currently provides the following tools/capabilities for data exploration and analysis:
- JupyterHub - JupyterHub brings the power of notebooks to groups of users
- pgweb - Cross-platform client for PostgreSQL databases
- AWS Redshift - AWS hosted columnar optimized data warehouse
- Elastic Stack - Distributed document database, ETL, and visualization tools
JupyterHub
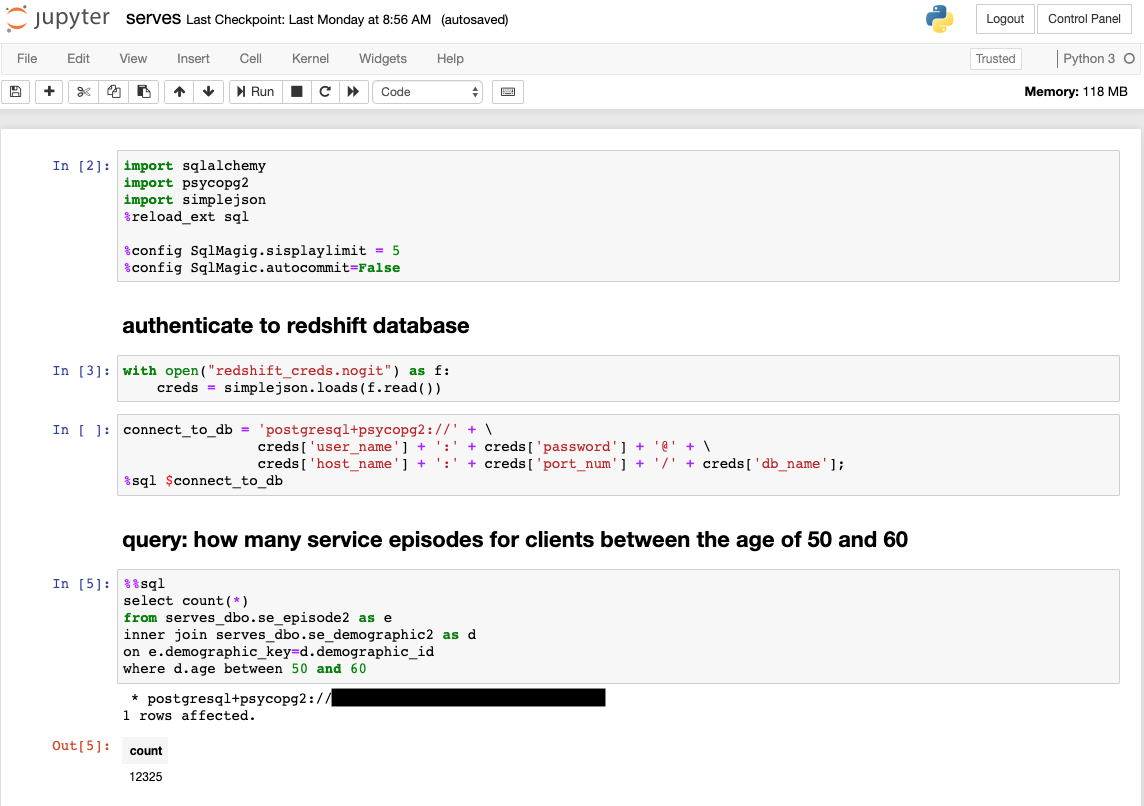
Jupyter notebooks have become the de facto standard for how to share reproducible research, and are used by companies and colleges all over the world. JupyterHub provides DCA users with a familiar interface by which they can run code in Python, R, and many other languages in order to analyze and visualize the data loaded into DCA. The screenshot below shows an example of how a user can use JupyterHub to run a notebook (Python kernel) that connects to a database and runs a query; in this case the query returns how many service episodes for clients between the age 50 and 60.
PostgreSQL/Pgweb
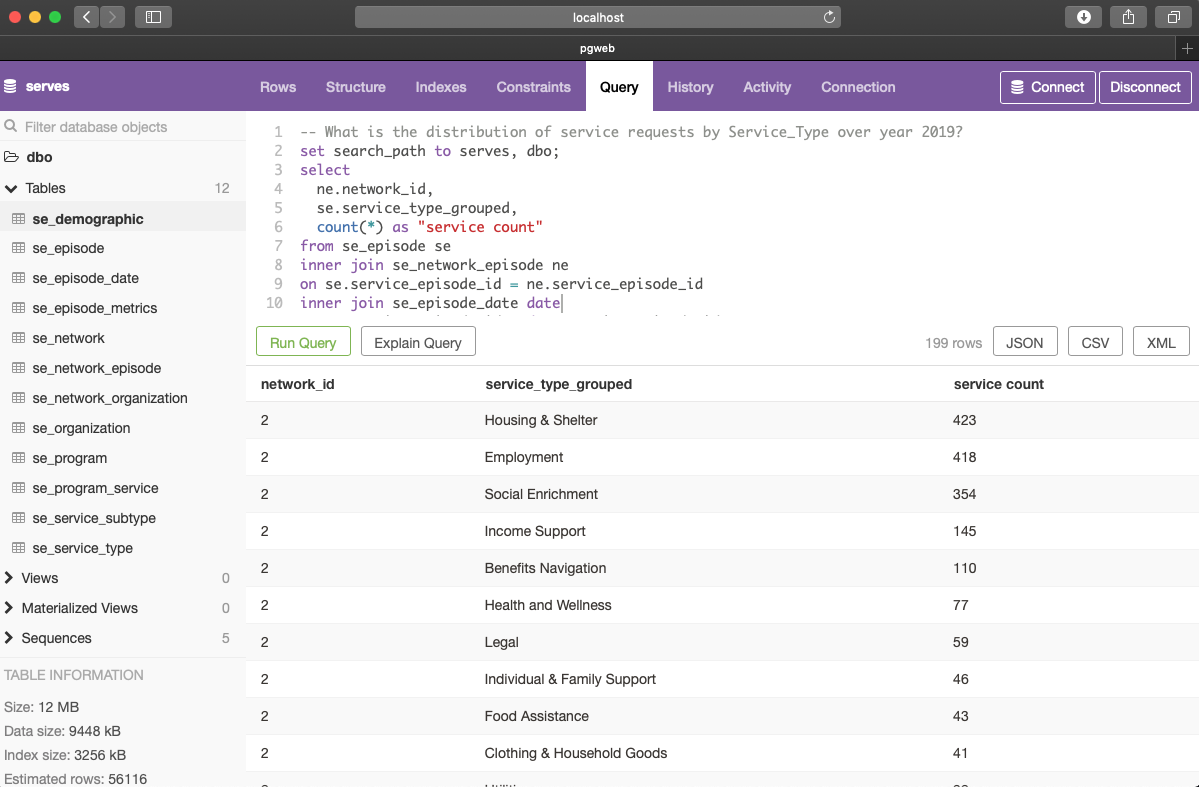
Pgweb is a cross-platform, web-interface for PostgreSQL databases. In the JupyterHub example above, DCA users interact with the backend database through programming languages such as Python or R. Pgweb provides another way to interact with the database by using Structured Query Language (SQL), and doesn’t require DCA users to set up a programming environment; only a web-browser is needed. The example below demonstrates a SQL query to find the distribution of service requests.
Elastic Stack (also know as ELK)
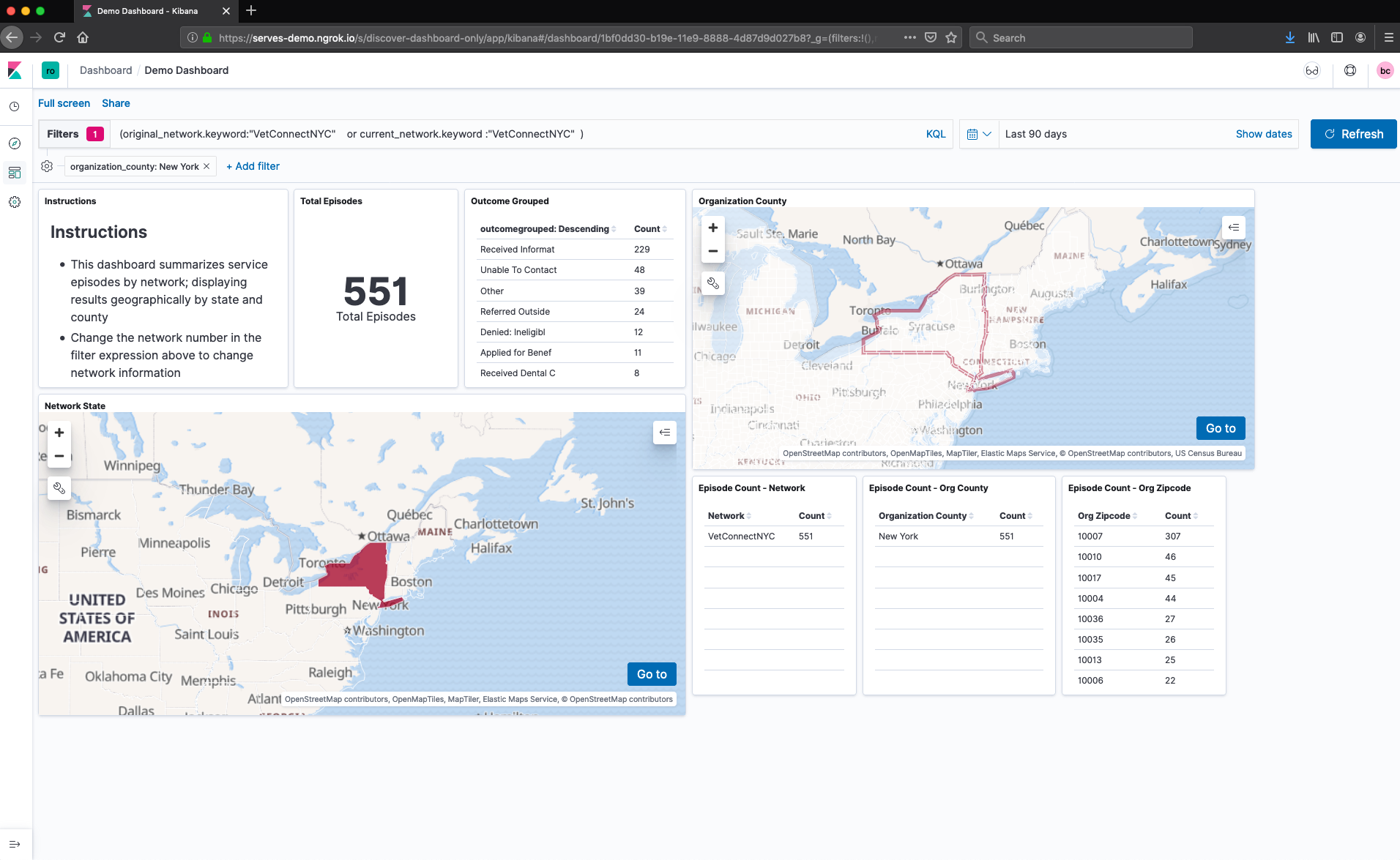
The Elastic Stack is a distributed document database that integrates with streaming and batch data shippers (i.e. Spark, Hadoop) as well as with relational databases. Data ingested into the ELK Stack is visualized using Kibana. Kibana allows users to iteratively discover/analyze data using user-friendly widgets and build dashboards of common visualizations (i.e. pie/bar/line charts, geo maps, etc.) The Elastic Stack is the recommended DCA tool for users without programming/SQL experience or for stakeholders that just want to view dashboards. The example below shows the total service episodes in the last 90 days (July ‘19) in the VetConnectNYC network. Additionally, the dashboard shows the distribution of service requests by county, zipcode, and outcome.
Redshift
Redshift is a data warehouse solution offered by AWS and was initially used as the database for DCA. However Redshift is a columnar datastore that is designed for column optimized queries over gigabytes/terabytes of data. Furthermore, while Redshift uses indices to guide query plans, primary/foreign keys for the indices are not enforced (import for BI, transactional analysis). Thus, we assessed that while Redshift could technically support DCA database requirements, Redshift is optimized for big data–which DCA currently doesn’t have.