Overview
The Elastic Stack is a distributed document database that integrates with streaming and batch data shippers (i.e. Spark, Hadoop) as well as with relational databases. Data ingested into the ELK Stack is visualized using Kibana. Kibana allows users to iteratively discover/analyze data using user-friendly widgets and build dashboards of common visualizations (i.e. pie/bar/line charts, geo maps, etc.) The Elastic Stack is the recommended DCA tool for users without programming/SQL experience or for stakeholders that just want to view dashboards.
Components of the Elastic Stack
- Elasticsearch: Elasticsearch is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases
- Logstash: Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite “stash.”
- Kibana: Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack so you can do anything from tracking query load to understanding the way requests flow through your apps.
Installation
Docker was used to orchestrate the build of the Elastic Stack. The Docker code (docker-compose, Docker files) is at this github repository
- Launch an EC2 instance in DCA
- Clone the repository to the instance
git clone '' - Build the Elastic Stack by running:
docker-compose up
Updating data in Elasticsearch database
When the Elastic Stack is compiled using “docker-compose up”, a local directory (/logstash/data) from the EC2 instance is binded to logstash container instance at path “/usr/share/logstash/data”. Logstash is configured to read csv files from the latter directory, process the csv files, and ingest into the Elasticsearch database. To update the data in the Elastic Stack, upload a new csv (i.e new SE_final.csv) file to the EC2 instance prior to running “docker-compose up”. The diagram below outlines the directory structure and data flow for this process.
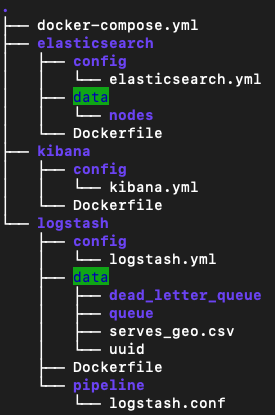
The csv file in the ./logstash/data directory, currently (serves_geo.csv), is the file that needs to be replaced to update data. Modifications to the transformations/cleaning steps will be made in the ./logstash/pipeline/logstash.conf file. Refer to the following resources for a more in-depth explanation of Logstash data extraction and transformation functions.